Trust the fungus!
Katherine Smith Awesome Site
EGO Search
2025-10-06
Retrieval augmented generation (RAG) is the process of retrieving information for use by an LLM. During training, an LLM learns semantic relationships between words and retains some encoding of the knowledge contained in its training dataset. This knowledge, however, can be out-of-date, incorrect, or hallucinated. RAG systems supply a LLM with external information in order to reduce the rate at which these issues occur.
I’ve been working with retrieval augmented generation as part of my job. We’re generating a knowledge base by feeding an LLM a bunch of pieces of text and then use that knowledge base to answer queries. It uses fancy techniques and I should not talk about it too much here. Anyway, it uses an LLM for a lot of that. Having a ten-year-old laptop, it’s not something that I’m in a position to run locally. And even if I could, that’s still an entire LLM we’re talking about. I do not want to pay for the electricity to run that!
Sometimes all we want to do is search through a text and locate semantically relevant information. A common and efficient method for doing this is to use vector RAG. An encoder model can translate the semantic meaning of a text into a vector known as an embedding. This is the “encoder” part of an LLM and in GPT-style models it is significantly smaller than the “decoder” part. Semantically similar texts create embeddings that are close together in this vector space, clustering relevant information together. These embeddings can be stored in a vector database, which is then queried with the embedding of a query text in order to find the most relevant results. Standard vector RAG is commonly achieved in this way by splitting a document into chunks of text, storing them in a vector database using their embeddings, and then selecting relevant chunks close to the embedding of a query.
This works pretty well! It does retrieve a lot of information, though, and isn’t as useful to a human as it is to an LLM. LLMs also operate under a contained context window (basically how much information we can supply it with) because too much context becomes computationally nightmarish. So I want to make this much more fine-grained…
Two questions arise:
- What if we make the segments really really small?
- How do I handle if something is split across the boundaries of these segments?
This is the part of the article where I introduce Embedding Group Overlap (EGO) Search! Embedding Group Overlap breaks a document into segments composed of sentences or words. These segments are far smaller than the chunks typically used in existing vector RAG systems, but are formed into overlapping groups for which embedding vectors are generated. These embedding vectors are compared with that of an input query to determine the relevance score for each group. Each segment is assigned a relevance score that is the sum of the relevance scores of the groups in which it appears. Because each segment appears in multiple groups, a segment receives a higher score if it appears in a greater number of relevant groups.
Let’s have an example! You have the collection of sentences “now for something completely different,” “things I like to bake,” “cake is one thing,” and “oh also cats are nice.” We generate some groups from these segments. In this minimal example those are “now for something completely different things I like to bake,” “things I like to bake cake is one thing” and “cake is one thing oh also cats are nice.” We generate embeddings for those and an embedding for a query text like “do I like to bake cake?” Groups 1 and 2 score most highly in this, so segment 2 receives a very high score because it appears in both of those groups.
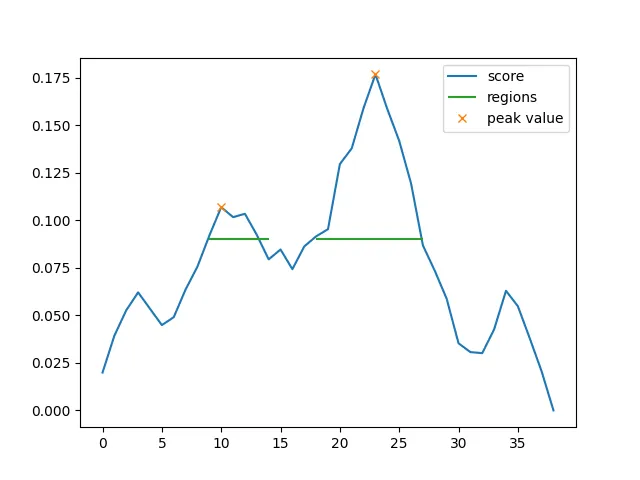
Once we’ve scored the segments, we identify peaks in the score values. We then descend the peak to some cutoff value (in the graph example the 65th percentile) to identify “regions” of text similar to the query text. The algorithm outputs a list of these regions sorted by their peak score (though one could use other metrics, I just haven’t tried that yet).
A neat property of this is that a “segment” can be smaller than a sentence! For my demo I ran EGO Search with sentence-level segments and then ran it again at a word level on the resulting region. It works pretty well! It’s also, like, the main innovation of this work, so I’d sure hope that it works pretty well.
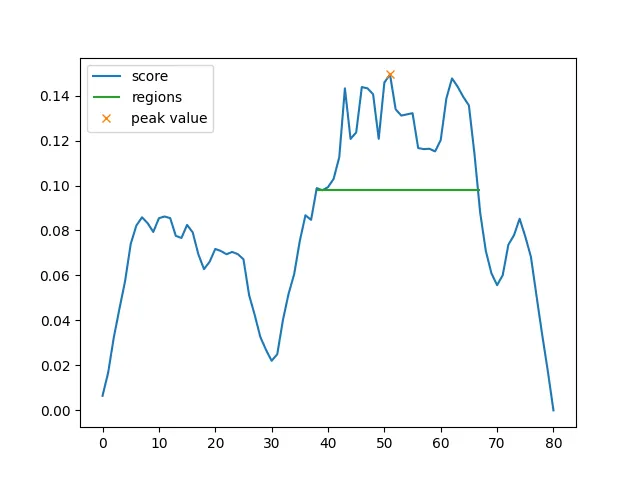
So is it efficient? Hahaha… no. But kind of maybe yes actually? There is a lot of redundant computation in the “overlap” part of the EGO Search. The computation of embedding vectors for a document isn’t too bad though, and needs only to be performed once. After that there’s the cost the many similarity comparisons but maybe that’s a price worth paying? EGO Search is a smart-ish kind of search, and might be the optimal solution if simple searches don’t cut it.
{kind=link}
{kind=link}
EGO Search uses text embeddings to retrieve information at a scalable resolution. It’s able to retrieve semantically-relevant parts of a text and their surrounding context without the computational price of a full LLM. I think it’s pretty neat :). The technique of overlapping embeddings and groups could be applicable in other areas beyond searching, too! In the future I’d like to try using it to create semantic sections of text, something like a semantic sorting algorithm.
I’ve made a poster for it and I’ll be presenting it at the ACM Celebration of Cascadia Women in Computing 2025 Student Poster session.
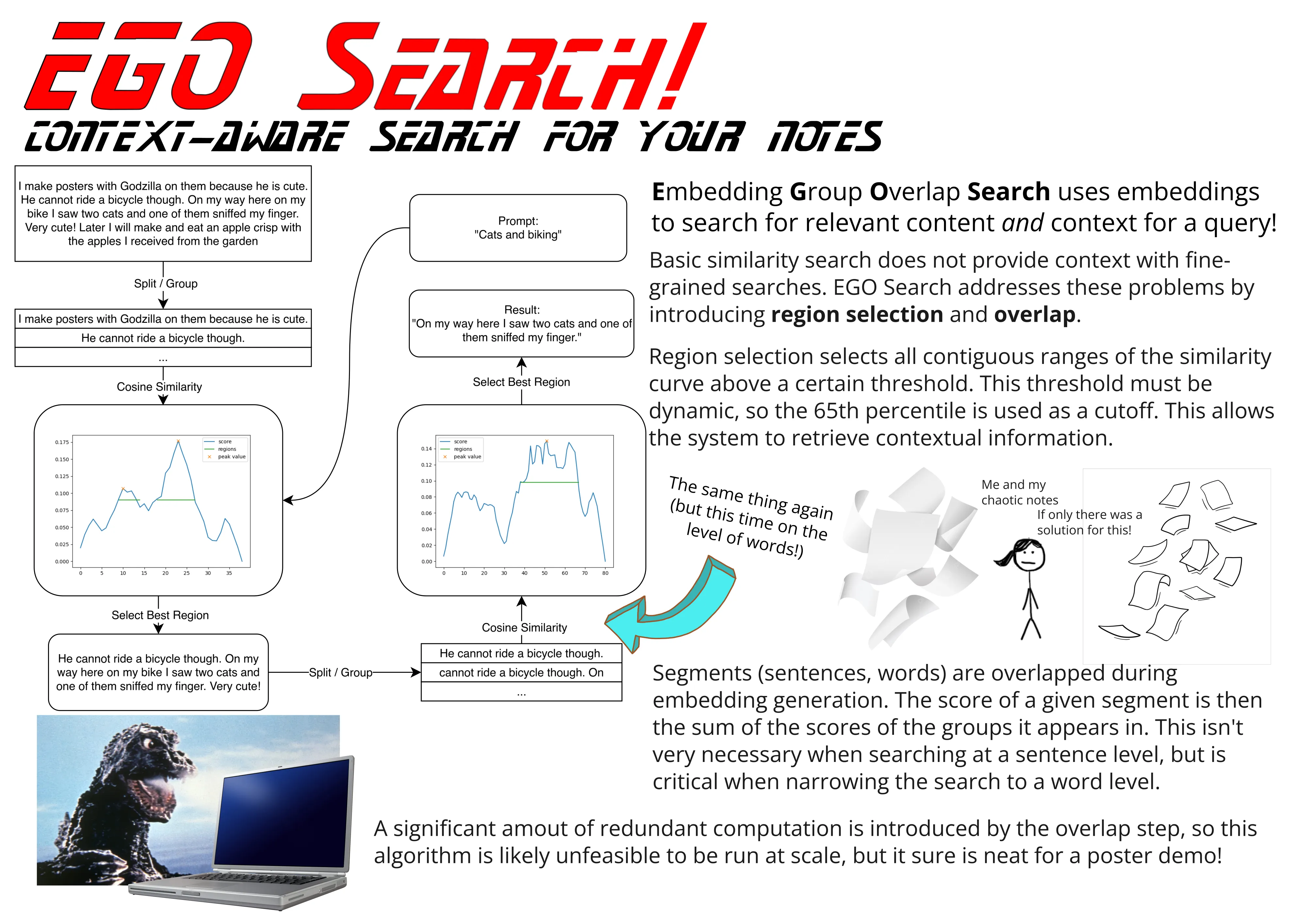
(yes I did consider using the “G” in EGO Search for “Godzilla” instead of “Group” and while that would have been cooler it would’ve made less sense)
Update: The poster session had awesome presenters and tasty snacks! I ate way too much cheese.
3D Noise Scaling
2025-02-07
Prior to beta 1.8, Minecraft had a particular style of terrain that appeals to me greatly. There are many factors that contribute to this. Low movement speed, high rates of weirdness, and chaotic biome placement are all important factors in the experience.
While developing Pinefruit, I wanted to recreate the experience of old Minecraft terrain. As a first step I needed to generate the shape of the terrain itself. There are many factors that go into generating Minecraft’s terrain. A key aspect that is often overlooked, however, is the blockiness of the density noise used to determine the surface’s shape.
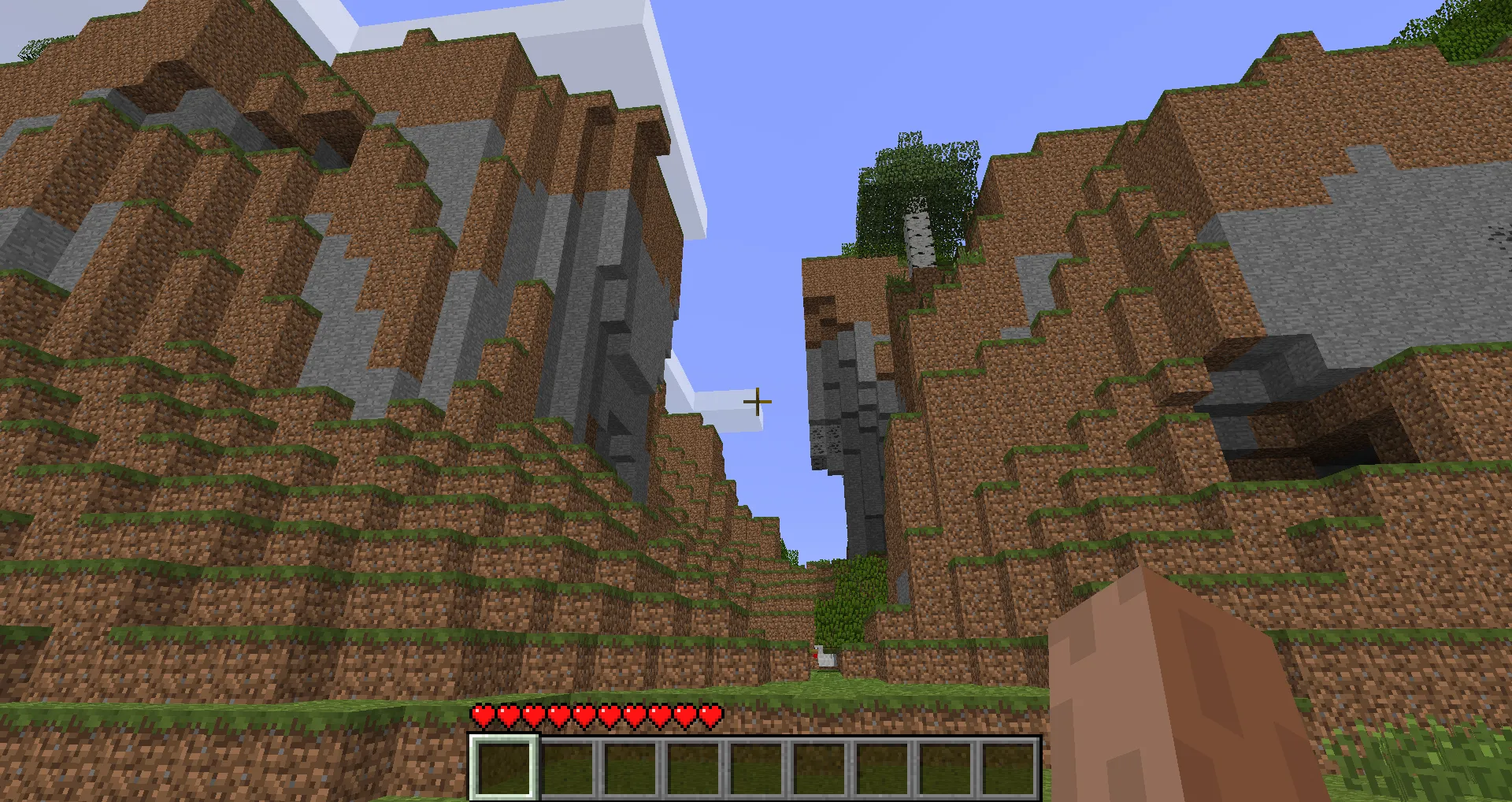
Here we can see a valley between two hills. What I’d like for you to notice is that the hills are kind of square looking.
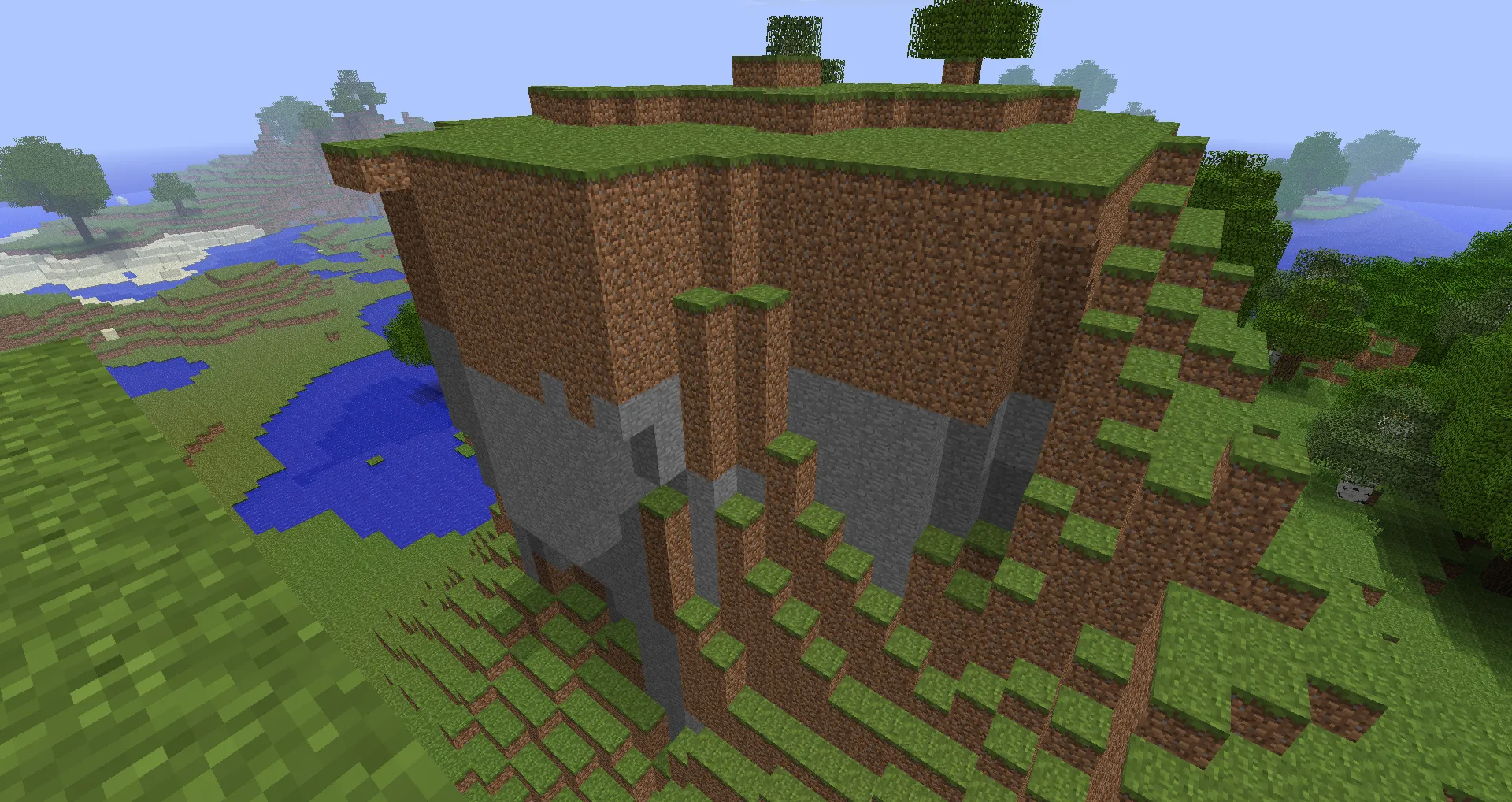
We can see it more clearly here. It’s neat. It’s blocky. It has a distinctive look to it. But why is it that way and how can we recreate it?
I’m not good at dramatic buildup. It’s a product of 3d noise interpolation. Minecraft interpolates its density noise, presumably in an attempt to reduce computational load. It’s just an extension of linear interpolation into 3d.
fn lerp(x: f32, x1: f32, x2: f32, q00: f32, q01: f32) -> f32 {
((x2 - x) / (x2 - x1)) * q00 + ((x - x1) / (x2 - x1)) * q01
}
fn lerp3(
x: f32, y: f32, z: f32,
q000: f32, q001: f32, q010: f32, q011: f32, q100: f32, q101: f32, q110: f32, q111: f32,
x1: f32, x2: f32, y1: f32, y2: f32, z1: f32, z2: f32,
) -> f32 {
let x00 = lerp(x, x1, x2, q000, q100);
let x10 = lerp(x, x1, x2, q010, q110);
let x01 = lerp(x, x1, x2, q001, q101);
let x11 = lerp(x, x1, x2, q011, q111);
let r0 = lerp(y, y1, y2, x00, x01);
let r1 = lerp(y, y1, y2, x10, x11);
lerp(z, z1, z2, r0, r1)
}It’s simple to add this to our terrain generator. This works pretty well, but it’s rather inefficient. Scaling a 8x8x8 volume to 16x16x16 with this takes 114,564.06ns. Just generating a 16x16x16 noise volume takes 113,809.63ns, which is (just barely) faster!
My first order of business was to refactor that lerp3 code to reduce the number of divisions.
In the following code, the t values are the factor of each axis and the q values are the values at each octant.
fn lerp(a: f32, b: f32, t: f32) -> f32 {
a * (1.0 - t) + b * t
}
fn lerp3(
xt: f32, yt: f32, zt: f32,
q000: f32, q001: f32, q010: f32, q011: f32, q100: f32, q101: f32, q110: f32, q111: f32,
) -> f32 {
let x00 = lerp(q000, q100, xt);
let x10 = lerp(q010, q110, xt);
let x01 = lerp(q001, q101, xt);
let x11 = lerp(q011, q111, xt);
let r0 = lerp(x00, x01, zt);
let r1 = lerp(x10, x11, zt);
lerp(r0, r1, yt)
}This works pretty well. Now we are doing the same task in 95,697.39ns. For this application I only need to scale the noise by an integer factor, and this gives me some more opportunities for optimization.
I tried skipping noise interpolation at values where all t values will be zero. When doubling the scale of a noise volume, this would reduce the work by 12.5%. Oddly enough, this was a bad idea. When scaling noise from 8x8x8 to 16x16x16, we experience a slowdown of nearly 14% (95,574.26ns vs 110,722.50ns). That’s not so great.
As another avenue, I realized that I could precompute the t values rather than computing them for each cell.
At the beginning of the function I create an array on the stack which stores the t values for a cell at offset i at index i.
When inside the loop, we can fetch the precomputed value instead of performing a floating-point division.
let mut t_vals = [0.0; MAX_SCALE];
for i in 0..scale {
t_vals[i] = i as f32 / scale as f32;
}
for cell in cells {
...
let d = cell - (cell / scale) * scale;
let xt = t_vals[0][d.x as usize];
let yt = t_vals[1][d.y as usize];
let zt = t_vals[2][d.z as usize];
...
}I used this code to generate 16x16x16 volumes of noise, analogous to a chunk in Minecraft. Without interpolation the noise was generated in 109,302.56ns. With interpolation scaling from 8x8x8, the noise was generated in 89,285.23ns. That’s a win, being 22% faster than without this optimization!
In the beginning we were generating noise volumes in 114,564.06ns, and now we are generating them in 89,285.23ns. I’ve had fun optimizing this and my optimizations actually worked. This is acceptable to me.
But Minecraft also uses per-axis interpolation. Chunks of size 16x16x16 are generated from 8x8x4 volumes of noise. My code was built with this in mind, and it’s pretty much ready to go. But oh no! The crate I’m using to generate the noise values, simdnoise, does not allow for per-axis frequency scaling. A pull request added the feature five years ago, but there have been no new releases since then! Even though it would be simple, I’m still too lazy to pull the thing from github directly. I’ve put it in the backlog for now, and hopefully we’ll be able to experiment with that eventually.