Trust the fungus!
Katherine Smith Awesome Site
EGO Search
2025-10-06
Retrieval augmented generation (RAG) is the process of retrieving information for use by an LLM. During training, an LLM learns semantic relationships between words and retains some encoding of the knowledge contained in its training dataset. This knowledge, however, can be out-of-date, incorrect, or hallucinated. RAG systems supply a LLM with external information in order to reduce the rate at which these issues occur.
I’ve been working with retrieval augmented generation as part of my job. We’re generating a knowledge base by feeding an LLM a bunch of pieces of text and then use that knowledge base to answer queries. It uses fancy techniques and I should not talk about it too much here. Anyway, it uses an LLM for a lot of that. Having a ten-year-old laptop, it’s not something that I’m in a position to run locally. And even if I could, that’s still an entire LLM we’re talking about. I do not want to pay for the electricity to run that!
Sometimes all we want to do is search through a text and locate semantically relevant information. A common and efficient method for doing this is to use vector RAG. An encoder model can translate the semantic meaning of a text into a vector known as an embedding. This is the “encoder” part of an LLM and in GPT-style models it is significantly smaller than the “decoder” part. Semantically similar texts create embeddings that are close together in this vector space, clustering relevant information together. These embeddings can be stored in a vector database, which is then queried with the embedding of a query text in order to find the most relevant results. Standard vector RAG is commonly achieved in this way by splitting a document into chunks of text, storing them in a vector database using their embeddings, and then selecting relevant chunks close to the embedding of a query.
This works pretty well! It does retrieve a lot of information, though, and isn’t as useful to a human as it is to an LLM. LLMs also operate under a contained context window (basically how much information we can supply it with) because too much context becomes computationally nightmarish. So I want to make this much more fine-grained…
Two questions arise:
- What if we make the segments really really small?
- How do I handle if something is split across the boundaries of these segments?
This is the part of the article where I introduce Embedding Group Overlap (EGO) Search! Embedding Group Overlap breaks a document into segments composed of sentences or words. These segments are far smaller than the chunks typically used in existing vector RAG systems, but are formed into overlapping groups for which embedding vectors are generated. These embedding vectors are compared with that of an input query to determine the relevance score for each group. Each segment is assigned a relevance score that is the sum of the relevance scores of the groups in which it appears. Because each segment appears in multiple groups, a segment receives a higher score if it appears in a greater number of relevant groups.
Let’s have an example! You have the collection of sentences “now for something completely different,” “things I like to bake,” “cake is one thing,” and “oh also cats are nice.” We generate some groups from these segments. In this minimal example those are “now for something completely different things I like to bake,” “things I like to bake cake is one thing” and “cake is one thing oh also cats are nice.” We generate embeddings for those and an embedding for a query text like “do I like to bake cake?” Groups 1 and 2 score most highly in this, so segment 2 receives a very high score because it appears in both of those groups.
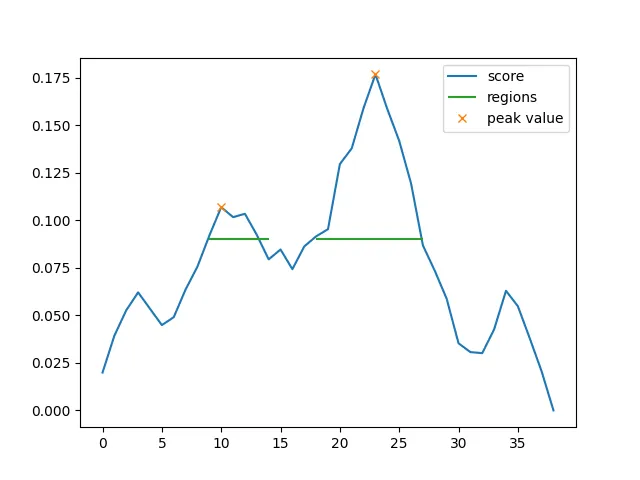
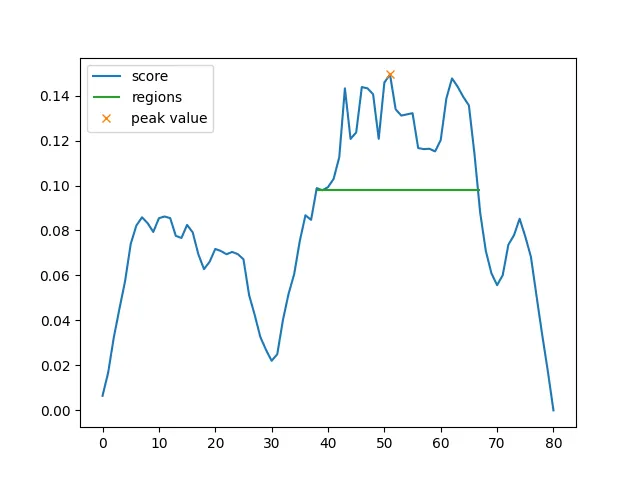
Once we’ve scored the segments, we identify peaks in the score values. We then descend the peak to some cutoff value (in the graph example the 65th percentile) to identify “regions” of text similar to the query text. The algorithm outputs a list of these regions sorted by their peak score (though one could use other metrics, I just haven’t tried that yet).
A neat property of this is that a “segment” can be smaller than a sentence! For my demo I ran EGO Search with sentence-level segments and then ran it again at a word level on the resulting region. It works pretty well! It’s also, like, the main innovation of this work, so I’d sure hope that it works pretty well.
So is it efficient? Hahaha… no. But kind of maybe yes actually? There is a lot of redundant computation in the “overlap” part of the EGO Search. The computation of embedding vectors for a document isn’t too bad though, and needs only to be performed once. After that there’s the cost the many similarity comparisons but maybe that’s a price worth paying? EGO Search is a smart-ish kind of search, and might be the optimal solution if simple searches don’t cut it.
{kind=link}
{kind=link}
EGO Search uses text embeddings to retrieve information at a scalable resolution. It’s able to retrieve semantically-relevant parts of a text and their surrounding context without the computational price of a full LLM. I think it’s pretty neat :). The technique of overlapping embeddings and groups could be applicable in other areas beyond searching, too! In the future I’d like to try using it to create semantic sections of text, something like a semantic sorting algorithm.
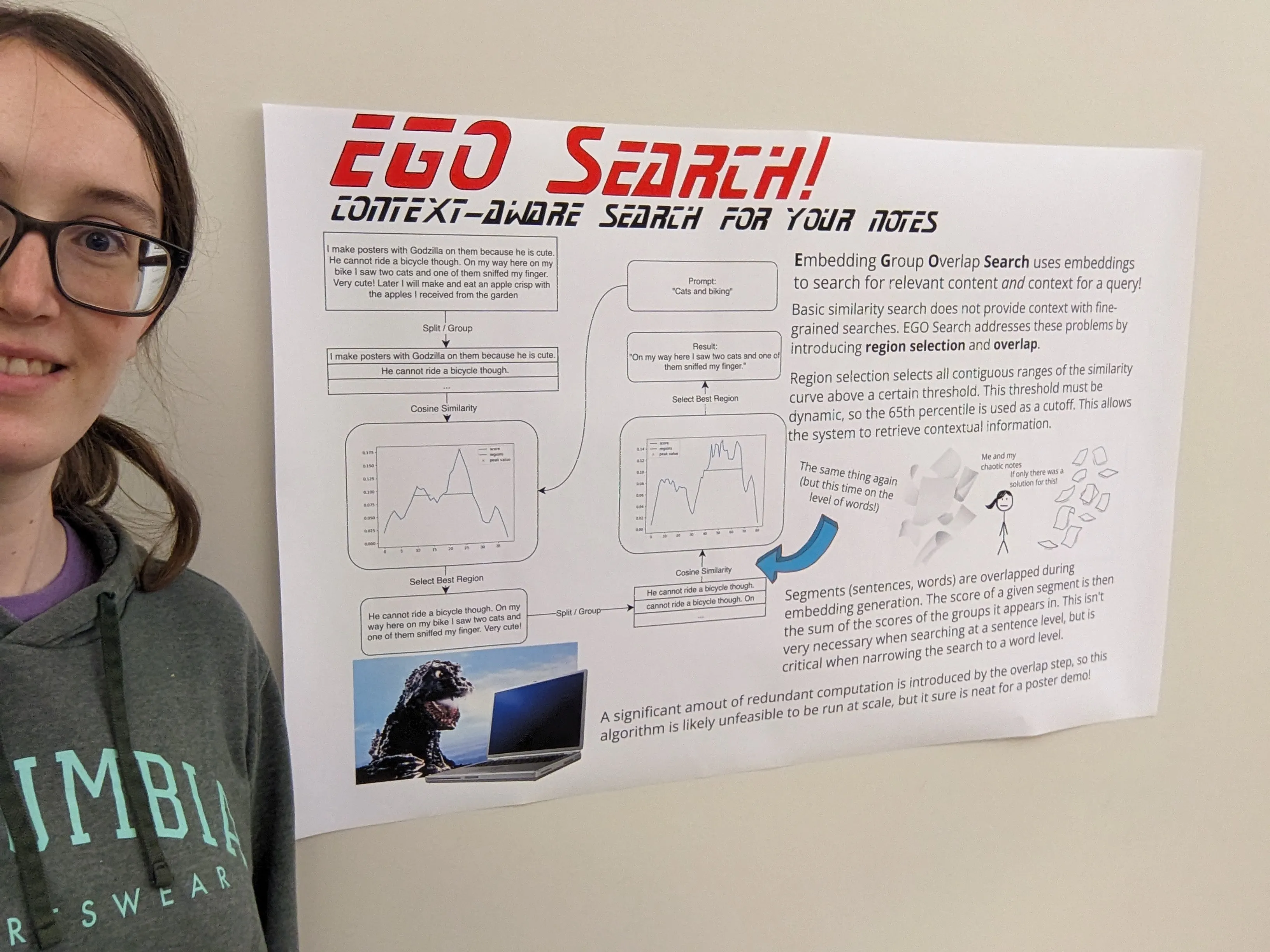
I’ve made a poster for it and I’ll be presenting it at the ACM Celebration of Cascadia Women in Computing 2025 Student Poster session.
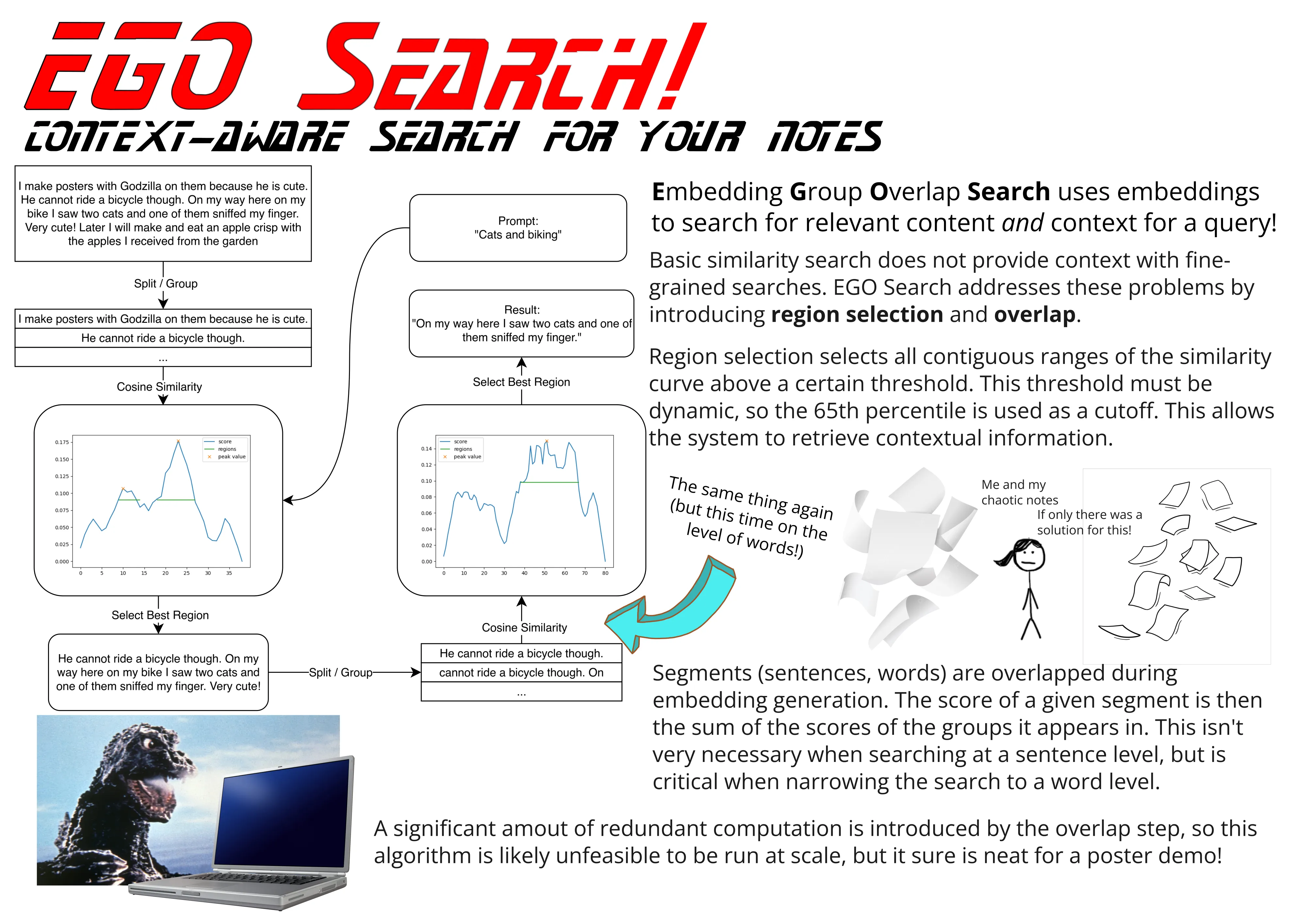
(yes I did consider using the “G” in EGO Search for “Godzilla” instead of “Group” and while that would have been cooler it would’ve made less sense)
Update: The poster session had awesome presenters and tasty snacks! I ate way too much cheese.